9. Stateful Properties
Stateful property tests are particularly useful when "what the code should do"—what the user perceives—is simple, but "how the code does it"—how it is implemented—is complex. A large amount of integration and system tests fit this very specific mode of operations, and stateful property-based testing becomes one of the most interesting tools to have in a developer’s toolbox since it can exercise major parts of the system with little code.
Stateful property tests are a non-formal variation on model checking, built as a higher level abstraction on top of stateless property-based tests. The core concept of stateful tests in quickcheck-like frameworks is to define a (mostly) deterministic model of the system, generate a series of commands that represent the execution flow, and then run them on the real system under test. Throughout the execution, the real system is compared to the model to validate that the expectations hold true. If they don’t, the test fails.
9.1. Basics
There are three major components for stateful tests:
-
the model
-
the generation of commands representing the execution flow
-
the validation of the system against the model
The model is made of two parts:
-
A data structure representing the expected state of the system
-
A series of functions that transform the model state based on operations that could be applied to the system, representing its changes when executed
The generation of commands itself is also based on two parts:
-
A list of potential symbolic calls, with generators defining their arguments
-
A series of functions that defines whether a given symbolic call would make sense to apply according to the current model state.
The latter point is interesting. The functions that validate if a call is acceptable in a sequence are called 'preconditions', and they define invariants that should hold true in the system for the current test. For example, it is possible that an ATM only exposes functionality to deposit money if a debit card is inserted; a precondition of depositing money would therefore be that a valid debit card is currently in the ATM. Preconditions are the stateful equivalent to ?SUCHTHAT macros in stateless properties.
Finally, there is the validation of the system against the model. The functions for those are called 'postconditions' and are invariants that should hold true after a given operation has been applied. For example, if a model’s state tells that a user has inserted their card, and that the operation that was just executed was the user typing in the wrong password, then the postcondition would validate that the actual system properly returns a failure to log in. Such postcondition validation can be done by checking global invariants that are expected to always hold, but also frequently takes place by comparing the system’s output with the expected result (based on the model state).
In a nutshell, the components for a stateful test are:
-
a model composed of some state and functions to modify that state
-
commands generated through symbolic calls, validated by precondition functions
-
postcondition functions that compare actual system results with those expected based on the model
9.2. Execution Model
The execution of a stateful test is divided in two phases, one abstract and one real. The abstract phase is used to create a test scenario, and is executed without any system code running:
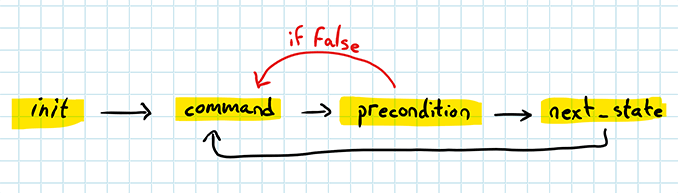
In the abstract mode, a potential command (with its arguments) is generated from an initial model state. The preconditions for the command are then validated. If this validation fails, a new command is generated until one is seen as valid. Once a suitable command is found, the state transition for this command is applied to the model state, and the next command is generated in a similar manner. The framework is in charge of choosing when to stop based on the desired complexity. Once the process is over, a valid and legitimate sequence of commands will have been generated.
Once a command sequence is in place, the actual execution can take place:
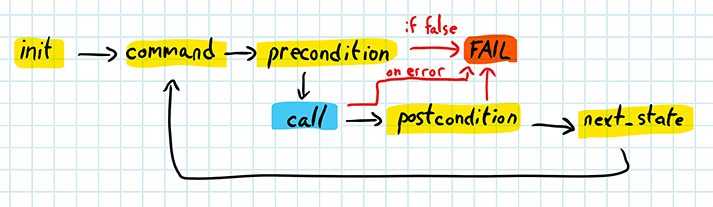
The execution phase runs the generated command sequence against the real system. The preconditions are still re-evaluated to ensure consistency so that if a generated precondition that used to work suddenly fails, the entire test also fails. The next symbolic call in the list is executed, with its result stored. The postcondition is then evaluated, and if it succeeds, the state transition for the command is applied to the state and the next command can be processed.
In case of a failure, shrinking is done by modifying the command sequence as required. Preconditions will be used by the framework to make sure that the various state transitions attempted are valid.
9.3. Structure of Properties
Stateful properties can be used to test simple systems to extremely complex ones, and as such, their structure may vary from project to project. There is nevertheless a common set of functionality present with all of them:
-module(prop_stateful).
-include_lib("proper/include/proper.hrl").
-export([command/1, initial_state/0, next_state/3,
precondition/2, postcondition/3]).
prop_test() ->
?FORALL(Cmds, commands(?MODULE), (1)
begin
actual_system:start_link(), (2)
{History, State, Result} = run_commands(?MODULE, Cmds), (3)
actual_system:stop(), (4)
?WHENFAIL(io:format("History: ~p\nState: ~p\nResult: ~p\n",
[History,State,Result]),
aggregate(command_names(Cmds), Result =:= ok))
end).
-record(state, {}).
%% Initial model value at system start. Should be deterministic.
initial_state() -> (5)
#state{}.
command(_State) -> (6)
oneof([
{call, actual_system, some_call, [term(), term()]}
]).
%% Picks whether a command should be valid under the current state.
precondition(#state{}, {call, _Mod, _Fun, _Args}) -> (7)
true.
%% Given the state `State' *prior* to the call `{call, Mod, Fun, Args}',
%% determine whether the result `Res' (coming from the actual system)
%% makes sense.
postcondition(_State, {call, _Mod, _Fun, _Args}, _Res) -> (8)
true.
%% Assuming the postcondition for a call was true, update the model
%% accordingly for the test to proceed.
next_state(State, _Res, {call, _Mod, _Fun, _Args}) -> (9)
NewState = State,
NewState.| 1 | Auto-imported function to do command generation |
| 2 | Setup for test iteration (such as setting up external dependencies if any) |
| 3 | Test execution command through an auto-imported function |
| 4 | Teardown function to clean up the state |
| 5 | Model’s initial state; should be deterministic |
| 6 | Command generation. Can be based on the model’s state to go faster, but preconditions will still be used when shrinking. |
| 7 | Precondition. If it returns true to a given command, it will be used. Returning false will force a new attempt at generating a command. |
| 8 | Postcondition. The result of the actual system execution is in _Res. |
| 9 | Transition the model’s state. The value for _Res will be a symbolic placeholder during symbolic execution. Treat as an opaque value that cannot be modified. |
This essentially contains most of the test structure that will be required.
|
The two execution flows are important to keep in mind: since the calls to preconditions, commands, and state transitions are executed both when generating commands and when running the actual system, side-effects should be avoided in the model. And any value coming from the actual system that gets transferred to the model should be treated as an opaque blob that cannot be inspected, be matched against, or be used in a function call that aims to transform it. Instead, the values should be used only to communicate with the real system itself. Because the abstract phase has to pass some of these values in to make them available to the model, but that the system is not running to provide the data, placeholders are actually used by frameworks like PropEr. Those placeholders are the reason why the data must be treated as opaque. This is very abstract for now, but the core concept to keep in mind is that the model is the source of authority that drives the test execution, not the system. |
|
Erlang’s Quickcheck has different callbacks for this form of testing. They are logically equivalent, but the form is based on function names. See the eqc_statem documentation for details. |
9.4. Basic Sequential Cache
To put stateful tests in practice, a simple cache will be tested. The cache has a fairly simple behaviour:
-
The cache can have a maximal number of items
-
Once the max size is reached, the oldest written value is replaced (not the last one read, which would be a more expected behaviour)
-
If an item is overwritten, even with a changed value, the cache entry remains in the same position
-
The cache can be emptied on-demand
Since the rules are straightforward, the implementation is pretty simple as well:
-module(cache).
-export([start_link/1, stop/0, cache/2, find/1, flush/0]). (1)
-behaviour(gen_server).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2]). (2)
start_link(N) ->
gen_server:start_link({local, ?MODULE}, ?MODULE, N, []).
stop() ->
gen_server:stop(?MODULE).
find(Key) -> (3)
case ets:match(cache, {'_', {Key, '$1'}}) of
[[Val]] -> {ok, Val};
[] -> {error, not_found}
end.
cache(Key, Val) ->
case ets:match(cache, {'$1', {Key, '_'}}) of % find dupes
[[N]] -> (4)
ets:insert(cache, {N,{Key,Val}}); % overwrite dupe
[] ->
case ets:lookup(cache, count) of % insert new
[{count,Max,Max}] -> (5)
ets:insert(cache, [{1,{Key,Val}}, {count,1,Max}]);
[{count,Current,Max}] -> (6)
ets:insert(cache, [{Current+1,{Key,Val}},
{count,Current+1,Max}])
end
end.
flush() -> (7)
[{count,_,Max}] = ets:lookup(cache, count),
ets:delete_all_objects(cache),
ets:insert(cache, {count, 0, Max}).
init(N) -> (8)
ets:new(cache, [public, named_table]),
ets:insert(cache, {count, 0, N}),
{ok, nostate}.
handle_call(_Call, _From, State) -> {noreply, State}.
handle_cast(_Cast, State) -> {noreply, State}.
handle_info(_Msg, State) -> {noreply, State}.| 1 | Public API |
| 2 | Callback exports |
| 3 | Finding keys is done through scanning an ETS table with match/2 |
| 4 | Duplicate values are overwritten |
| 5 | When the table is full, the values get overwritten from the beginning of the list of entries |
| 6 | Otherwise entries are just added incrementally |
| 7 | The cache gets flushed by removing all the entries and resetting its counters |
| 8 | The worker is only used to maintain the ETS table in memory and initialize its state |
The test execution for the property looks as follows:
-module(prop_cache).
-include_lib("proper/include/proper.hrl").
-export([command/1, initial_state/0, next_state/3,
precondition/2, postcondition/3]).
-define(CACHE_SIZE, 10).
prop_test() ->
?FORALL(Cmds, commands(?MODULE),
begin
cache:start_link(?CACHE_SIZE),
{History, State, Result} = run_commands(?MODULE, Cmds),
cache:stop(),
?WHENFAIL(io:format("History: ~p\nState: ~p\nResult: ~p\n",
[History,State,Result]),
aggregate(command_names(Cmds), Result =:= ok))
end).An arbitrary cache size has been chosen for the sake of simplicity. A generator could also have been used for more thorough testing.
Important to note is that the setup and teardown functions (cache:start_link/1 and cache:stop/0) run as part of the property, every time. Putting them in the surrounding code will not work, as the ?FORALL macro returns an abstract data structure representing the test to run. Only the code that is part of the macro will be run at test time.
The state for the model maintains the strict minimum required to be able to do any sort of validation:
-record(state, {max=?CACHE_SIZE, count=0, entries=[]}).
%% Initial model value at system start. Should be deterministic.
initial_state() ->
#state{}.The command generation is straightforward as well. It has been decided to put emphasis on writes for the tests through the use of the frequency/1 generator, and to not flush the cache while it is empty:
command(_State) ->
frequency([
{1, {call, cache, find, [key()]}},
{3, {call, cache, cache, [key(), val()]}},
{1, {call, cache, flush, []}}
]).
%% Picks whether a command should be valid under the current state.
precondition(#state{count=0}, {call, cache, flush, []}) ->
false; % don't flush an empty cache for no reason
precondition(#state{}, {call, _Mod, _Fun, _Args}) ->
true.Do note that command generation is intimately tied to preconditions. One cannot realistically be expected without the other. In fact, any important selection logic should take place in the precondition function.
The generators for key() and val() are defined as:
key() ->
oneof([range(1,?CACHE_SIZE), % reusable keys, raising chance of dupes
integer()]). % random keys
val() ->
integer().The generator for keys is designed to allow some keys to be repeated multiple time. By using a restricted set of keys (with the range/2 generator) along with a much wider one, the generator should help exercising any code related to key reuse or matching, but without losing the ability to 'fuzz' the system.
The next_state callback completes command generation by allowing the model to keep up to date with what the system state should be:
%% Assuming the postcondition for a call was true, update the model
%% accordingly for the test to proceed.
next_state(State, _, {call, cache, flush, _}) ->
State#state{count=0, entries=[]}; (1)
next_state(S=#state{entries=L, count=N, max=M}, _Res,
{call, cache, cache, [K, V]}) ->
case lists:keyfind(K, 1, L) of
false when N =:= M -> S#state{entries = tl(L) ++ [{K,V}]}; (2)
false when N < M -> S#state{entries = L ++ [{K,V}], count=N+1}; (3)
{K,_} -> S#state{entries = lists:keyreplace(K,1,L,{K,V})} (4)
end;
next_state(State, _Res, {call, _Mod, _Fun, _Args}) ->
State. (5)| 1 | Flushing the cache resets the state (apart from the max number of entries) |
| 2 | When the cache is at capacity, the first element is dropped (tl(L)) before adding the new one at the end |
| 3 | When the cache still has free place, the entry is added at the end, and the counter incremented |
| 4 | If the entry key is a duplicate, it replaces the old one without refreshing it |
| 5 | All other calls (reading the cache) do not impact the state |
With this in place, command generation can take place. The only thing left to do for a complete execution is to check postconditions:
%% Given the state `State' *prior* to the call `{call, Mod, Fun, Args}',
%% determine whether the result `Res' (coming from the actual system)
%% makes sense.
postcondition(#state{entries=L}, {call, cache, find, [Key]}, Res) ->
case lists:keyfind(Key, 1, L) of
false -> Res =:= {error, not_found};
{Key, Val} -> Res =:= {ok, Val}
end;
postcondition(_State, {call, _Mod, _Fun, _Args}, _Res) ->
true.In this model validation, only reading the system has an impact. If the keys that are readable or not always match, then the writing and flushing has to be correct.
Running the tests yield good results:
$ rebar3 proper -m prop_cache -n 1000
[...]
===> Testing prop_cache:prop_test()
......................................................[...]
OK: Passed 1000 test(s).
63% {cache,cache,2}
21% {cache,find,1}
14% {cache,flush,0}Injecting a failure to see if things make sense can however demonstrate proper test failure. For example, replacing the initialization call to:
init(N) ->
ets:new(cache, [public, named_table]),
ets:insert(cache, {count, 0, N-1}),
{ok, nostate}.should ensure failures, since the maximal count between the model (N) and the system (N-1) differ, and varying entries should be dropped.
Running the tests with this broken code does show a failure:
===> Testing prop_cache:prop_test()
.....[...].....!
Failed: After 747 test(s).
[{set,{var,1},{call,cache,find,[8]}},[...]] (1)
History: [{{state,10,0,[]},{error,not_found}},
[...]]
State: {state,10,10, [...]}
Result: {postcondition,false}
Shrinking ......(6 time(s)) (2)
[{set,{var,5},{call,cache,cache,[10,36]}},[...], (3)
{set,{var,18},{call,cache,find,[10]}}]
History: [{{state,10,0,[]},true},
{{state,10,1,[{10,36}]},true}, (4)
{{state,10,2,[{10,36},{-19,-6}]},true},
{{state,10,3,[{10,36},{-19,-6},{12,5}]},true},
[...]
{{state,10,10,[{10,36},{-19,-6},{12,5},{9,26},{-4,-30},{-75,17},
{13,-22},{42,5},{31,55},{197,18}]},
{error,not_found}}]
State: {state,10,10, [{10,36},{-19,-6},{12,5},{9,26},{-4,-30},{-75,17},{13,-22},
{42,5},{31,55},{197,18}]} (5)
Result: {postcondition,false} (6)| 1 | The initial failing test case with all the data from ?WHENFAIL. Usually so large it is unreadable. |
| 2 | Shrinking of the test. The following data is usually simpler to read. |
| 3 | The list of commands representing the minimal representable failing case |
| 4 | A sequence of all the model states visited with the result from the call. The format is a list of {State, Result} tuples. Following the history along with commands can help see what yielded what.[1] |
| 5 | The final state at the time of the failure |
| 6 | The reason why the postcondition failed (usually false). |
The data shows that the last call to find(10) had the system return {error, not_found} whereas the internal state contains a tuple {10,36}. The shrinking also failed at the limit of the counter with the value 10 as well. With all of that data, identifying the bug and fixing it is hopefully doable. At the very least, finding unexpected mistakes and bugs is simple enough.
9.5. Parallel Tests
One of the most interesting features of such tests has to do with being able to parallelize tests automatically. The mechanism works by taking the existing command sequence, finding it a common root, and then splitting it up in concurrent timelines. Given the command sequence:
A -> B -> C -> D -> E -> F -> GBased on the generators, PropEr can transform it into the sequence:
,-> C -> E -> G
A -> B
'-> D -> FAnd run the branches in parallel, in order to find whether all the pre- and postconditions still hold. The command set given is returned as a tuple of the form {SequentialRoot, [LeftBranch, RightBranch]} once transformed, which means that if any analysis of generated commands was being done in ?WHENFAIL, it will need to change.
The parallel version of the test for the cache would be:
prop_parallel() ->
?FORALL(Cmds, parallel_commands(?MODULE), (1)
begin
cache:start_link(?CACHE_SIZE),
{History, State, Result} = run_parallel_commands(?MODULE, Cmds), (2)
cache:stop(),
?WHENFAIL(io:format("=======~n"
"Failing command sequence:~n~p~n"
"At state: ~p~n"
"=======~n"
"Result: ~p~n"
"History: ~p~n",
[Cmds,
State,Result,History]),
aggregate(command_names(Cmds), Result =:= ok))
end).The only changes are that parallel_commands/1 and run_parallel_commands/2 are used instead of commands/1 and run_commands/2, respectively. The cost of writing parallel tests is surprisingly low once a basic model has been written.
This is good, because out of the box, the parallel tests for PropEr do not find a lot of bugs. This is partly because of the Erlang scheduler and partly because of the framework itself. People who want strong parallel tests may want to use QuickCheck, which has better detection and tooling, but also offers PULSE, a user-level scheduler that can be used to augment concurrency.[2] If stateful property-based testing is used to test external systems written in other languages, then there can still be decent value in parallel tests as well.
PropEr users can also increase the ability of finding bugs by giving the Erlang virtual machine the +T9 argument (increasing the scheduler aggressiveness)[3], but even this is not guaranteed to find any bugs even in very buggy programs.
For example, with the cache program, running even 1,000 tests finds nothing. However, if the code is instrumented with instructions to preempt it:
cache(Key, Val) ->
case ets:match(cache, {'$1', {Key, '_'}}) of % find dupes
[[N]] ->
ets:insert(cache, {N,{Key,Val}}); % overwrite dupe
[] ->
erlang:yield(), (1)
case ets:lookup(cache, count) of % insert new
[{count,Max,Max}] ->
ets:insert(cache, [{1,{Key,Val}}, {count,1,Max}]);
[{count,Current,Max}] ->
ets:insert(cache, [{Current+1,{Key,Val}},
{count,Current+1,Max}])
end
end.
flush() ->
[{count,_,Max}] = ets:lookup(cache, count),
ets:delete_all_objects(cache),
erlang:yield(), (2)
ets:insert(cache, {count, 0, Max}).| 1 | Deschedule the process between two lookups to raise the chance of making bad decision |
| 2 | Deschedule the process between a deletion and an insertion to increase the chance of having missing data in another process' lookup |
Then PropEr finds bugs very rapidly:
[...]
===> Testing prop_cache:prop_parallel()
.!
Failed: After 2 test(s). (1)
An exception was raised: error:{'EXIT',{{case_clause,[]},[{cache,cache,2,[...],{line,24},...]}
Stacktrace: [...]. (2)
{[],[[...],[...]]}
Shrinking ......(6 time(s))
{[],[[{set,{var,2},{call,cache,cache,[6,0]}},{set,{var,3},{call,cache,flush,[]}}],[{set,{var,7},{call,cache,cache,[0,-1]}}]]}| 1 | Elided Stacktrace for the program |
| 2 | PropEr’s own stacktrace due to program failure |
With preemption, PropEr detects a failure that is fairly simple to reproduce, with no need for a common root. The call history decomposes as:
,-> cache(6,0) -> flush()
0 --+
'-> cache(0,-1)Reverse-engineering a race condition is a bit complex, but in this case, the issue is likely just due to cache(0,1) failing when it gets descheduled in-between the two destructive operations of flush(), and while caching tries to access the counter of the table that is no longer there.
Fixing the bug requires making sure that all destructive updates to the cache are done in a serialized manner. This could be done with locks, but an easier fix is to move write operations within the process that owns the table:
-module(cache).
-export([start_link/1, stop/0, cache/2, find/1, flush/0]).
-behaviour(gen_server).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2]).
start_link(N) ->
gen_server:start_link({local, ?MODULE}, ?MODULE, N, []).
stop() ->
gen_server:stop(?MODULE).
find(Key) ->
case ets:match(cache, {'_', {Key, '$1'}}) of
[[Val]] -> {ok, Val};
[] -> {error, not_found}
end.
cache(Key, Val) ->
gen_server:call(?MODULE, {cache, Key, Val}).
flush() ->
gen_server:call(?MODULE, flush).
%%%%%%%%%%%%%%%
%%% Private %%%
%%%%%%%%%%%%%%%
init(N) ->
ets:new(cache, [public, named_table]),
ets:insert(cache, {count, 0, N}),
{ok, nostate}.
handle_call({cache, Key, Val}, _From, State) ->
case ets:match(cache, {'$1', {Key, '_'}}) of % find dupes
[[N]] ->
ets:insert(cache, {N,{Key,Val}}); % overwrite dupe
[] ->
erlang:yield(),
case ets:lookup(cache, count) of % insert new
[{count,Max,Max}] ->
ets:insert(cache, [{1,{Key,Val}}, {count,1,Max}]);
[{count,Current,Max}] ->
ets:insert(cache, [{Current+1,{Key,Val}},
{count,Current+1,Max}])
end
end,
{reply, ok, State};
handle_call(flush, _From, State) ->
[{count,_,Max}] = ets:lookup(cache, count),
ets:delete_all_objects(cache),
erlang:yield(),
ets:insert(cache, {count, 0, Max}),
{reply, ok, State}.
handle_cast(_Cast, State) -> {noreply, State}.
handle_info(_Msg, State) -> {noreply, State}.While the reads can still be done concurrently within the callers, the critical write-related code paths have been moved to a single process (the table owner), which acts as a serializer. The tests now pass:
===> Testing prop_cache:prop_parallel()
.......f.........................................................f...[...]
OK: Passed 1000 test(s).
63% {cache,cache,2}
21% {cache,find,1}
15% {cache,flush,0}Each f stands for a non-parallelizable command generation that failed and had to be retried. Otherwise, everything is clear, even with the erlang:yield() calls in place.
The next chapter will show a more advanced and thorough example of stateful tests.