6. Case Study: Stateless Properties with Birthday Wishes
This chapter is an example of using property-based testing in a standard-looking application, based on the rather classic exercises of TDD enthusiasts, the birthday greetings kata. The exercise aims to practice test organization in such a way that as few of them need to be modified or trashed when implementation details change.
6.1. The Specification
The requirement is to write a program that:
-
Loads a set of employee records from a flat file
-
Sends a greeting email to all employees whose birthday is today
The flat file is a sequence of records looking a bit like a comma-separated values (CSV) file. The sample given contains:
last_name, first_name, date_of_birth, email
Doe, John, 1982/10/08, john.doe@foobar.com
Ann, Mary, 1975/09/11, mary.ann@foobar.comThe e-mail sent should contain text like:
Subject: Happy birthday!
Happy birthday, dear John!
On its own, this is straightforward. The challenge comes from the additional constraints given:
-
The tests written should be unit tests, meaning none of the tests should: talk to a database; touch the filesystem; interact with the network; toy with the environment (config). Tests that do any of these are qualified as integration tests and are out of scope.
-
The CSV format won’t be kept forever. Eventually, a database or web service will be used to fetch the employee records, and similarly for the e-mail sending. The tests should be written to require as few modifications as possible whenever these implementations change.
6.2. Thinking About Program Structure
The additional challenge forces some system thinking before jumping to properties. The known requirements are:
-
load employee records from flat file
-
send a greetings email to employees whose birthday is today
-
the employee records look vaguely like CSV although the exact format is unspecified
-
the backend storage can change entirely (including moving from files to a database or service)
-
leap years exist and should be handled
-
unit tests are free of interactions with the host system
In traditional object-oriented code, the tools of the trade would be Dependency Injection (DI). Object-oriented design tends to confine side-effects within specific objects as part of its encapsulation work towards separation of concerns. In doing so, each bit of side-effects can be reasoned about within the limited scope of an object. On the other hand, the end result is often a system that has side-effects strewn all over. Dependency Injection allows the overriding of the behaviour of individual objects that are depended on (removing all side-effects in the process) so that test runs can be fully isolated to a specific class at a time.
In the case of functional programming languages, the lesson taught by pure languages like Haskell is that side-effects can be grouped together at one end of the system, and have the rest of the code as pure as possible. Most programming languages that are not Haskell can follow these principles, but will rely on programmer discipline to do so.[1]
The side-effects in the program should be:
-
Loading records from a flat file
-
Finding today’s date
-
Sending an e-mail
These tasks can still be broken down further:
Side-Effects |
Functional |
Reading a flat file |
Converting CSV data to employee records |
Finding a date |
Using a given date in a search for employees |
Sending an e-mail |
Formatting the e-mail as a string |
Things are a bit clearer. Everything on the left column will go in integration tests (not covered in this exercise), and everything on the right can go in unit tests. In fact, the whole system could be built on this separation:
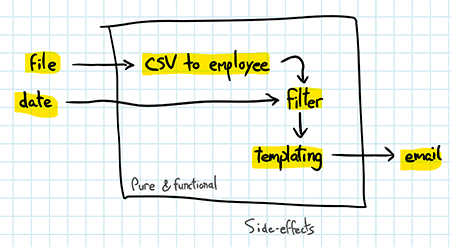
Everything in the box should be pure and functional, everything outside of it will provide side-effects. The 'main' function will have the responsibility of tying both universes together. With this approach, the program becomes a sequence of transformations carried over known (but configurable) bits of data. This structure is not cast in stone, but should be a fairly good guideline that ensures strict decoupling of components.
6.3. Planning
There are two general ways to tackle such a program design and implementation:
-
Top-down: tends to make it easier to write a program with the user’s perspective, properly hiding non-essential concerns. On the other hand, the initial perspective from the user tends not to know about all the hidden complexity (some of which might be essential). This in turn tends to force major rework and re-thinking of the original perspective.
-
Bottom-up: by writing basic components first, they can then be wired up and assembled into a greater system. If done too organically, this can yield a messy system with limited cohesion as individual pieces end up fitting together poorly.
Since the top-level view is already there, and that the focus will be on tests, the latter approach feels adequate. The building blocks to be assembled are:
-
CSV parsing of terms into maps
-
Filtering of objects based on date/time (if the program were using SQL or a service, it would be handled there; in this case it will be local and require testing)
-
Putting the filtering and CSV parsing together into an 'employee' module providing a well-isolated interface
-
Templating of the email and subject to be sent based on the employee data
The part remaining should be a rather simple top-level module that wires these components together. Actual e-mails will not be sent, since they are a bit out of scope given the focus is on unit tests.
6.4. CSV Parsing
CSV is a loose specification that nobody really implements the same, although there is an RFC for it (RFC 4180).
In short:
-
Each record is on a separate line, separated by CRLF
-
The last record of the file may or may not have a CRLF after it
-
The first line of the file may be a header line, ended with a CRLF. In this case, the problem description includes a header, which will be assumed to always be there
-
Commas go between fields of a records
-
Any spaces are considered to be part of the record (the example in the problem description does not respect that, adding a space after each comma)
-
Double-quotes (
") can be used to wrap a given record -
fields that contain line-breaks (CRLF), double-quotes, or commas must be wrapped in double quotes
-
All records in a document contain the same number of fields
-
A double-quote within a double-quoted field can be escaped by preceding it with another double-quote (
"a""b"meansa"b) -
field values or header names can be empty
-
Valid characters for records include only:
! #$%&'()*+-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~`
As far as CSV parsing is concerned, the CSV will be used as an authority. If the provided data does not match CSV fully, it will be the responsibility of those providing the data, or those consuming it, to correct the format (such as removing leading spaces). It is simpler to reason about systems when components are well-defined and use adaptors when needed than thinking about systems when all components are unique snowflakes.
Before writing the tests, choosing the type of property to be used is important. The three main strategies could be:
-
Modeling: make a simpler less efficient version of CSV parsing and compare it to the real one.
-
Rules: generalize what would be a standard unit test of dumping data, reading it and making sure it matches expectations.
-
Symmetric testing: serialize and unserialize the data, ensuring results are the same.
Symmetric testing is the most tempting one for parsers and serializers. Since validating decoding requires encoded data, and that encoded data requires decoding to be validated, both sides of encoding and decoding will be required no matter what. Plugging both into a single property is often ideal. The property can then be anchored with a few traditional unit tests from the RFC itself to make sure expectations are met.
The first generators to write are those related to CSV fields:
field() -> oneof([unquoted_text(), quotable_text()]).
unquoted_text() -> list(elements(textdata())).
quotable_text() -> list(elements([$\r, $\n, $", $,] ++ textdata())).
textdata() ->
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"
":;<=>?@ !#$%&'()*+-./[\\]^_`{|}~".The overall approach will be to generate Erlang data structures that will be converted to CSV and then back to Erlang data structures. This explains why the field() generator calls to both 'unquoted' and 'quotable' text generators: the unquoted generator should result in fields that do not require escaping through quotes, whereas the quotable generator will. The use of both generators will ensure the encoders and decoders are well-exercised in both cases. Also note that the textdata() generator puts alphanumeric characters first. That’s because the elements() generator shrinks towards the first elements of the list, meaning that in cases of failures, it will try to generate counterexamples that are more readable when possible.
The generated CSV data will have titles with known lengths, and similarly, records with known lengths. Reading the RFC, names can have exactly the same rules as records:
header(Size) -> vector(Size, name()).
record(Size) -> vector(Size, field()).
name() -> field().The internal data structure to represent records will be maps, since they allow for easy key-value lookups. The headers will be used as the keys and the records each as a value:
csv_source() -> (1)
?LET(Size, pos_integer(),
?LET(Keys, header(Size),
list(entry(Size, Keys)))).
entry(Size, Keys) -> (2)
?LET(Vals, record(Size),
maps:from_list(lists:zip(Keys, Vals))).| 1 | Generate headers (keys), and then use the headers to generate lists of Erlang maps |
| 2 | Generate an individual map with a given known size and list of keys |
Note the usage of nested ?LET macros. In csv_source(), if the pos_integer() generator were to be used directly as a size, then entries and headers may end up with different size value as each instance of the generator would be evaluated independently. Using a ?LET macro allows to make the Size variable hold a discrete value that will be the same in all contexts. The second ?LET can then be used for the generation of lists with maps with the same number of entries as there are keys.
The following property can then be used:
prop_roundtrip() ->
?FORALL(Maps, csv_source(),
Maps =:= hexa_csv:decode(hexa_csv:encode(Maps))).To run it successfully, both a parser and encoder and an encoder are needed. Here’s about 100 lines of code that implement both fully:
-module(hexa_csv).
-export([encode/1, decode/1]).
%% @doc Take a list of maps with the same keys and transform them
%% into a string that is valid CSV, with a header.
-spec encode([map()]) -> string().
encode([]) -> "";
encode(Maps) ->
Keys = string:join([escape(Name) || Name <- maps:keys(hd(Maps))], ","),
Vals = [string:join([escape(Field) || Field <- maps:values(Map)], ",")
|| Map <- Maps],
Keys ++ "\r\n" ++ string:join(Vals, "\r\n").
%% @doc Take a string that represents a valid CSV data dump
%% and turn it into a list of maps with the header entries as keys
-spec decode(string()) -> list(map()).
decode("") -> [];
decode(CSV) ->
{Headers, Rest} = decode_header(CSV, []),
Rows = decode_rows(Rest),
[maps:from_list(lists:zip(Headers, Row)) || Row <- Rows].
%%%%%%%%%%%%%%%
%%% PRIVATE %%%
%%%%%%%%%%%%%%%
%% @private return a possibly escaped (if necessary) field or name
-spec escape(string()) -> string().
escape(Field) ->
case escapable(Field) of
true -> "\"" ++ do_escape(Field) ++ "\"";
false -> Field
end.
%% @private checks whether a string for a field or name needs escaping
-spec escapable(string()) -> boolean().
escapable(String) ->
lists:any(fun(Char) -> lists:member(Char, [$",$,,$\r,$\n]) end, String).
%% @private replace escapable characters (only `"') in CSV.
%% The surrounding double-quotes are not added; caller must add them.
-spec do_escape(string()) -> string().
do_escape([]) -> [];
do_escape([$"|Str]) -> [$", $" | do_escape(Str)];
do_escape([Char|Rest]) -> [Char | do_escape(Rest)].
%% @private Decode the entire header line, returning all names in order
-spec decode_header(string(), [string()]) -> {[string()], string()}.
decode_header(String, Acc) ->
case decode_name(String) of
{ok, Name, Rest} -> decode_header(Rest, [Name | Acc]);
{done, Name, Rest} -> {[Name | Acc], Rest}
end.
%% @private Decode all rows into a list.
-spec decode_rows(string()) -> [[string()]].
decode_rows(String) ->
case decode_row(String, []) of
{Row, ""} -> [Row];
{Row, Rest} -> [Row | decode_rows(Rest)]
end.
%% @private Decode an entire row, with all values in order
-spec decode_row(string(), [string()]) -> {[string()], string()}.
decode_row(String, Acc) ->
case decode_field(String) of
{ok, Field, Rest} -> decode_row(Rest, [Field | Acc]);
{done, Field, Rest} -> {[Field | Acc], Rest}
end.
%% @private Decode a name; redirects to decoding quoted or unquoted text
-spec decode_name(string()) -> {ok|done, string(), string()}.
decode_name([$" | Rest]) -> decode_quoted(Rest);
decode_name(String) -> decode_unquoted(String).
%% @private Decode a field; redirects to decoding quoted or unquoted text
-spec decode_field(string()) -> {ok|done, string(), string()}.
decode_field([$" | Rest]) -> decode_quoted(Rest);
decode_field(String) -> decode_unquoted(String).
%% @private Decode a quoted string
-spec decode_quoted(string()) -> {ok|done, string(), string()}.
decode_quoted(String) -> decode_quoted(String, []).
%% @private Decode a quoted string
-spec decode_quoted(string(), [char()]) -> {ok|done, string(), string()}.
decode_quoted([$"], Acc) -> {done, lists:reverse(Acc), ""};
decode_quoted([$",$\r,$\n | Rest], Acc) -> {done, lists:reverse(Acc), Rest};
decode_quoted([$",$, | Rest], Acc) -> {ok, lists:reverse(Acc), Rest};
decode_quoted([$",$" | Rest], Acc) -> decode_quoted(Rest, [$" | Acc]);
decode_quoted([Char | Rest], Acc) -> decode_quoted(Rest, [Char | Acc]).
%% @private Decode an unquoted string
-spec decode_unquoted(string()) -> {ok|done, string(), string()}.
decode_unquoted(String) -> decode_unquoted(String, []).
%% @private Decode an unquoted string
-spec decode_unquoted(string(), [char()]) -> {ok|done, string(), string()}.
decode_unquoted([], Acc) -> {done, lists:reverse(Acc), ""};
decode_unquoted([$\r,$\n | Rest], Acc) -> {done, lists:reverse(Acc), Rest};
decode_unquoted([$, | Rest], Acc) -> {ok, lists:reverse(Acc), Rest};
decode_unquoted([Char | Rest], Acc) -> decode_unquoted(Rest, [Char | Acc]).The code was developed by running it against the single property multiple times. For brevity, I had to skip on a full bad implementation that did some odd dirty parsing. It worked with most obvious case, but once running the previous tests, it failed on this fun counterexample:
\r\naThis is technically a valid CSV file with a single column, for which the empty name "" is chosen (commas only split values, so a single CRLF means a 0-length string as a value on that line), and with a single value "a". The expected output from decoding this is [#{"" ⇒ "a"}]. The first version of the parser had no way to cope with such cases, and my brain had no way to imagine them either. The previous parser is considering such cases, but the digging and rewriting has been skipped for brevity.
The implementation however still fails on this tricky test:
hexa_csv:encode([#{[]=>[]},#{[]=>[]}]) => "\r\n\r\n"
hexa_csv:decode("\r\n\r\n") => [#{[] => []}]This is an ambiguity directly embedded directly in the CSV specification. Because a trailing \r\n is acceptable, it is impossible to know whether there is an empty trailing line or not in the case of 1-column data sets. Above one column, at least one comma (,) is going to be in the line. At one column, there is no way to know. Under 50 lines of tests were enough to discover inconsistencies in RFC 4180 itself, inconsistencies that cannot be reconciliated or fixed in our program.
Instead, tests will have to be relaxed to let the bug go through. This can be done by altering the csv_source() generator to always have 2 or more columns by adding +1 to every Size value generated, shifting the range from 1..N to 2..(N+1):
csv_source() ->
?LET(Size, pos_integer(),
?LET(Keys, header(Size+1),
list(entry(Size+1, Keys)))).After this change, the property works fine. For good measure, a unit test representing the known unavoidable bug should be added to the same test suite:
-module(prop_csv).
-include_lib("proper/include/proper.hrl").
-include_lib("eunit/include/eunit.hrl").
-compile(export_all).
[...]
%%%%%%%%%%%%%
%%% EUnit %%%
%%%%%%%%%%%%%
%% @doc One-column CSV files are inherently ambiguous due to
%% trailing CRLF in RFC 4180. This bug is expected
one_column_bug_test() ->
?assertEqual("\r\n\r\n", hexa_csv:encode([#{[]=>[]},#{[]=>[]}])),
?assertEqual([#{[] => []}], hexa_csv:decode("\r\n\r\n")).The suite can be run with rebar3 eunit as well as rebar3 proper (note the use of both prop_ as a prefix to the module and _tests as a suffix so the EUnit cases so tests are detected by both tools[2]).
There is a last gotcha implicit to the implementation of our CSV parser: since it uses maps, duplicate column names are not tolerated. Since this is to be used to represent a database, this is probably a fine assumption to make about the data set since the code making use of CSV data would likely also hold a similar constraint, much like it would be unlikely to be using single-column tables in a database. This gotcha was discovered by adding good old samples from the RFC into the EUnit test suite:
rfc_record_per_line_test() ->
?assertEqual([#{"aaa" => "zzz", "bbb" => "yyy", "ccc" => "xxx"}],
hexa_csv:decode("aaa,bbb,ccc\r\nzzz,yyy,xxx\r\n")).
rfc_optional_trailing_crlf_test() ->
?assertEqual([#{"aaa" => "zzz", "bbb" => "yyy", "ccc" => "xxx"}],
hexa_csv:decode("aaa,bbb,ccc\r\nzzz,yyy,xxx")).
rfc_double_quote_test() ->
?assertEqual([#{"aaa" => "zzz", "bbb" => "yyy", "ccc" => "xxx"}],
hexa_csv:decode("\"aaa\",\"bbb\",\"ccc\"\r\nzzz,yyy,xxx")).
rfc_crlf_escape_test() ->
?assertEqual([#{"aaa" => "zzz", "b\r\nbb" => "yyy", "ccc" => "xxx"}],
hexa_csv:decode("\"aaa\",\"b\r\nbb\",\"ccc\"\r\nzzz,yyy,xxx")).
rfc_double_quote_escape_test() ->
%% gotta cheat a bit since we mandate headers, so `CRLF,,' is added
%% to force values
?assertEqual([#{"aaa" => "", "b\"bb" => "", "ccc" => ""}],
hexa_csv:decode("\"aaa\",\"b\"\"bb\",\"ccc\"\r\n,,")).
%% @doc this counterexample is taken literally from the RFC and cannot
%% work with the current implementation because maps have no dupe keys
dupe_keys_unsupported_test() ->
CSV = "field_name,field_name,field_name\r\n"
"aaa,bbb,ccc\r\n"
"zzz,yyy,xxx\r\n",
[Map1,Map2] = hexa_csv:decode(CSV),
?assertEqual(1, length(maps:keys(Map1))),
?assertEqual(1, length(maps:keys(Map2))),
?assertMatch(#{"field_name" := _}, Map1),
?assertMatch(#{"field_name" := _}, Map2).The last test was impossible to write under the current implementation, so doing it by hand still proved worthwhile. In the end, ignoring comments and blank lines, there’s 27 lines of unit tests, and 19 lines of property-based tests. While the former let us find one 'gotcha' about our code and validates specific cases against the RFC, the latter let us exercise our code to the point we found inconsistencies in the RFC itself[3]. That’s impressive.
6.5. Filtering
In most non-local implementations, filtering and sorting would be provided at the interface level: in a SQL query or as arguments to an API for example. It would therefore not require tests at the unit level, mostly just integration ones if any. Filtering itself is straightforward: just use a standard library like lists:filter/2 and pass in the date to look for. What’s trickier is ensuring that the predicate passed to the function is correct.
Since the birthday search is based on 366 possible dates to verify, it could be reasonable to just run through all of them. In practice there’s a few more interleavings to consider: leap years, whether there’s more than one match, and so on. With a list of 366 employees (or 1098 to ensure more than one employee per day), each with their own birthday, and then run the program for every day of every year starting in 2017 (current year of this writing) until 2117, and making sure that each employee is greeted once per year on the same day as their birthday.
That gives slightly more than one million runs to cover the whole foreseeable future. A sample run lets us estimate how long it would be:
1> L = lists:duplicate(366*3, #{name => "a", bday => {1,2,3}}),
1> timer:tc(fun() ->
1> [lists:filter(fun(X) -> false end, L) || _ <- lists:seq(1,100*366)], ok
1> end).
{17801551,ok}Around 18 seconds. Not super fast, but not insufferable. This could be made faster by checking only 20 years, which takes under 3 seconds. That may be good enough to warrant bypassing unit tests and property-based testing altogether. Brute force it is. Heavy inspiration from properties will still make sense, with a fully deterministic data set replacing generators.
Then there are leap years. There’s a very well-known formula for this, Erlang implementing it in the calendar:is_leap_year/1 function (working on years >= 0). In case your language of choice does not have it, it looks a bit like this:
-spec is_leap_year(non_neg_integer()) -> boolean().
is_leap_year(Year) when Year rem 4 =:= 0, Year rem 100 > 0 -> true;
is_leap_year(Year) when Year rem 400 =:= 0 -> true;
is_leap_year(_) -> false.Using such a function, hand-rolling a full exhaustive property test is possible:
-module(hexa_filter_tests).
-include_lib("eunit/include/eunit.hrl").
%% Property
bday_filter_test() ->
Years = generate_years_data(2018,2038),
People = generate_people_for_year(3),
lists:foreach(fun(YearData) ->
Birthdays = find_birthdays_for_year(People, YearData),
every_birthday_once(People, Birthdays),
on_right_date(People, Birthdays)
end, Years).
find_birthdays_for_year(_, []) -> [];
find_birthdays_for_year(People, [Day|Year]) ->
Found = hexa_filter:birthday(People, Day), % <= function being tested
[{Day, Found} | find_birthdays_for_year(People, Year)].
%% Assertions
every_birthday_once(People, Birthdays) ->
Found = lists:sort(lists:append([Found || {_, Found} <- Birthdays])),
NotFound = People -- Found,
FoundManyTimes = Found -- lists:usort(Found),
?assertEqual([], NotFound),
?assertEqual([], FoundManyTimes).
on_right_date(_People, Birthdays) ->
[?assertEqual({M,D}, {PM,PD})
|| {{Y,M,D}, Found} <- Birthdays,
#{"date_of_birth" := {_,PM,PD}} <- Found].This tests assumes that 20 years of data will be generated, with 3 people born on each day. For each day of each year, the filter will extract everyone whose birthday is on that day. Then the set of people found will ensure that every birthday happens once, and that it happens on the right day.
The 'generators' are as follows:
%% Generators
generate_years_data(End, End) ->
[];
generate_years_data(Start, End) ->
[generate_year_data(Start) | generate_years_data(Start+1, End)].
generate_year_data(Year) ->
DaysInFeb = case calendar:is_leap_year(Year) of
true -> 29;
false -> 28
end,
month(Year,1,31) ++ month(Year,2,DaysInFeb) ++ month(Year,3,31) ++
month(Year,4,30) ++ month(Year,5,31) ++ month(Year,6,30) ++
month(Year,7,31) ++ month(Year,8,31) ++ month(Year,9,30) ++
month(Year,10,31) ++ month(Year,11,30) ++ month(Year,12,31).
month(Y,M,1) -> [{Y,M,1}];
month(Y,M,N) -> [{Y,M,N} | month(Y,M,N-1)].
generate_people_for_year(N) ->
YearSeed = generate_year_data(2016),
lists:append([people_for_year(YearSeed) || _ <- lists:seq(1,N)]).
people_for_year([]) ->
[];
people_for_year([Date|Year]) ->
[person_for_date(Date) | people_for_year(Year)].
person_for_date({_, M, D}) ->
#{"name" => make_ref(),
"date_of_birth" => {rand:uniform(100)+1900,M,D}}.One of two types of years are generated: leap or not. Then a set of every date is made for each year. People are generated similarly, but a unique name is given to each of them, along with a fairly random birth year.
Running the test with no implementation of course fails. Here’s the first implementation:
-module(hexa_filter).
-export([birthday/2]).
birthday(People, {_Year, Month, Date}) ->
lists:filter(
fun(#{"date_of_birth" := {_,M,D}}) -> {Month,Date} == {M,D} end,
People
).Running it fails in a fun way:
Failures:
1) hexa_filter_tests:bday_filter_test/0: module 'hexa_filter_tests'
Failure/Error: ?assertEqual([], NotFound)
expected: []
got: [#{"date_of_birth" => {1955,2,29},"name" => #Ref<0.0.1.2480>},
#{"date_of_birth" => {1909,2,29},"name" => #Ref<0.0.1.2846>},
#{"date_of_birth" => {1923,2,29},"name" => #Ref<0.0.1.3212>}]
%% lists.erl:1338:in `lists:foreach/2`Unsurprisingly, it seems it won’t find anyone’s leap birthday on a non-leap year. Code should be modified so that whenever it is Feb 28 on a non-leap year, birthdays are also searched for Feb 29 and the results are appended:
-module(hexa_filter).
-export([birthday/2]).
birthday(People, {Year, 2, 28}) ->
case calendar:is_leap_year(Year) of
true -> filter_dob(People, 2, 28);
false -> filter_dob(People, 2, 28) ++ filter_dob(People, 2, 29)
end;
birthday(People, {_Year, Month, Date}) ->
filter_dob(People, Month, Date).
filter_dob(People, Month, Date) ->
lists:filter(
fun(#{"date_of_birth" := {_,M,D}}) -> {Month,Date} == {M,D} end,
People
).Running this now fails on another case:
1) hexa_filter_tests:bday_filter_test/0: module 'hexa_filter_tests'
Failure/Error: ?assertEqual({2,28}, { PM , PD })
expected: {2,28}
got: {2,29}The test is now off since people whose birthday is on Feb 29 are greeted on the wrong day in non-leap years. To avoid sharing the implementation details between the code and the test, the test will be relaxed so that it accepts people being greeted on the wrong day when a birthday falls on an invalid date for the given year:
on_right_date(_People, Birthdays) ->
[calendar:valid_date({Y,PM,PD}) andalso ?assertEqual({M,D}, {PM,PD})
|| {{Y,M,D}, Found} <- Birthdays,
#{"date_of_birth" := {_,PM,PD}} <- Found].Now running the Eunit suite yields:
===> Performing EUnit tests...
........
Top 8 slowest tests (1.408 seconds, 95.6% of total time):
hexa_filter_tests:bday_filter_test/0: module 'hexa_filter_tests'
1.407 seconds
[...]Not too bad! Under 1.5 seconds for an exhaustive property-like test of the next 20 years of operation. It’s not property-based testing (although heavily inspired by it), but the results are more trustworthy since it’s going over all possibilities rather than some random selected ones.
6.6. Employee Module
All that stuff can be tied into a single employee module. Doing so will be interesting since it would be nice to avoid tying the module too much to its CSV sources, which also still have a few problems. The documented format was:
last_name, first_name, date_of_birth, email
Doe, John, 1982/10/08, john.doe@foobar.com
Ann, Mary, 1975/09/11, mary.ann@foobar.com-
the fields are messy and have extra spaces
-
the dates are in
"YYYY/MM/DD"format whereas Erlang works on{Year,Month,Day}tuples
The transformation requires additional processing after the conversion from CSV. This could usually be done or handled by a framework or adapter. For example, most PostgreSQL connection libraries will convert the internal data type for dates and time to Erlang’s {{Year,Month,Day}, {H,Min,Sec}} tuple format without much of a problem. In the case of CSV, the specification is really lax and as such the responsibility is to the consumer to covert from a string to the appropriate type, along with some additional validation.
At this point, the hexa_employee module will probably require:
-
a
from_csv/1function that takes a CSV string and returns a cleaned-up set of maps representing individual employees. Erlang’s opaque types can ensure (via Dialyzer) that nobody looks at that data set other than as a raw handle. This will allow to change data representations later, moving from CSV to a SQL-based iterator, for example. -
an accessor for each field (
last_name/1,first_name/1,date_of_birth/1,email/1) -
a function to find employees by birthday.
Since CSV conversion is already tested, the tests of the employee module should be purely about the clean up aspect. The hand-off from CSV to clean-up should be simple enough to contain no bugs. Starting with the test:
prop_fix_csv_leading_space() ->
?FORALL(Map, raw_employee_map(),
begin
Emp = hexa_employee:adapt_csv_result(Map),
Strs = [X || X <- maps:keys(Emp) ++ maps:values(Emp), is_list(X)],
lists:all(fun(String) -> hd(String) =/= $\s end, Strs)
end).This simple property checks that none of the text fields are prefixed with whitespace. The generators are as follows:
raw_employee_map() ->
%% PropEr does not have a native map type, so we convert
?LET(PropList,
[{"last_name", prop_csv:field()}, % 1st col has no built-in leading space
{" first_name", whitespaced_text()},
{" date_of_birth", text_date()},
{" email", whitespaced_text()}],
maps:from_list(PropList)).
whitespaced_text() ->
?LET(Txt, prop_csv:field(), " " ++ Txt).
text_date() ->
%% leading space and leading 0s for months and days
?LET({Y,M,D}, {choose(1900,2020), choose(1,12), choose(1,31)},
lists:flatten(io_lib:format(" ~w/~2..0w/~2..0w", [Y,M,D]))).This re-uses stuff from the CSV test module, and otherwise uses a narrower CSV generation. Running it fails for hexa_employee:adapt_csv_result/1 being undefined. In fact, users never have to call this one directly. It should be a private function. Conditional exports when in a test context can be used to keep it private while making it testable:
-module(hexa_employee).
-export([from_csv/1]).
-ifdef(TEST).
-export([adapt_csv_result/1]).
-endif.
-opaque employee() :: map().
-opaque handle() :: {raw, [employee()]}.
-export_type([handle/0, employee/0]).
-spec from_csv(string()) -> handle().
from_csv(String) ->
{raw, [adapt_csv_result(Map) || Map <- hexa_csv:decode(String)]}.
-spec adapt_csv_result(map()) -> employee().
adapt_csv_result(Map) ->
maps:fold(fun(K,V,NewMap) -> NewMap#{strip(K) => strip(V)} end,
#{}, Map).
strip(Str) -> string:strip(Str, left, $\s).The ifdef macro allows conditional exports, and the rest just implements a folding function that modifies every map from the result set. Running the properties finds a problem:
===> Testing prop_hexa_employee:prop_fix_csv_leading_space()
.!
Failed: After 2 test(s).
An exception was raised: error:badarg.
Stacktrace: [{erlang,hd,[[]],[]},
{prop_hexa_employee,'-prop_fix_csv_leading_space/0-fun-0-',1,
[{file,
"/Users/ferd/code/self/pbt/scratch/hexa/test/prop_hexa_employee.erl"},
{line,12}]},
{lists,all,2,[{file,"lists.erl"},{line,1213}]}].
[...]Of course, the first character of a string cannot be validated if the string is empty. It could be argued that empty source strings (if any) should instead be replaced by the atom undefined, or an equivalent of a NULL or other non-value in the host language. Making that change will implicitly fix the test since it filters out non-string results:[4]
-spec adapt_csv_result(map()) -> employee().
adapt_csv_result(Map) ->
maps:fold(fun(K,V,NewMap) -> NewMap#{strip(K) => maybe_null(strip(V))} end,
#{}, Map).
strip(Str) -> string:strip(Str, left, $\s).
maybe_null("") -> undefined;
maybe_null(Str) -> Str.The next requirement is to convert known dates (in the "dates_of_birth" field) to be under the internal Erlang date format:
prop_fix_csv_date_of_birth() ->
?FORALL(Map, raw_employee_map(),
case hexa_employee:adapt_csv_result(Map) of
#{"date_of_birth" := {Y,M,D}} ->
is_integer(Y) and is_integer(M) and is_integer(D);
_ ->
false
end).To make it pass, the following code is required:
adapt_csv_result(Map) ->
NewMap = maps:fold(
fun(K,V,NewMap) -> NewMap#{strip(K) => maybe_null(strip(V))} end,
#{},
Map
),
DoB = maps:get("date_of_birth", NewMap), % crash if key missing
NewMap#{"date_of_birth" => parse_date(DoB)}.
parse_date(Str) ->
[Y,M,D] = [list_to_integer(X) || X <- string:tokens(Str, "/")],
{Y,M,D}.Which will do the conversion once other map data has been corrected. Accessors can then be added. They should be so trivial they do not require testing:
-export([from_csv/1, last_name/1, first_name/1, date_of_birth/1, email/1]).
[...]
-spec last_name(employee()) -> string() | undefined.
last_name(#{"last_name" := Name}) -> Name.
-spec first_name(employee()) -> string() | undefined.
first_name(#{"first_name" := Name}) -> Name.
-spec date_of_birth(employee()) -> calendar:date().
date_of_birth(#{"date_of_birth" := DoB}) -> DoB.
-spec email(employee()) -> string().
email(#{"email" := Email}) -> Email.This lets people ignore the underlying map implementation. The birthday lookup can be tied up in another function so small it has to be right (and easily detectable in integration tests if not):
-spec filter_birthday(handle(), 1..12, 1..31) -> handle().
filter_birthday({raw, Employees}, Month, Day) ->
{raw, hexa_filter:birthday(Employees, Month, Day)}.The interesting gotcha about this implementation is that because it needs to be agnostic to the storage backend, an 'opaque' handling mechanism using the handle() type is used. Even though employee maps are used directly, the handle adds some indirection through the type system. People must access result sets through a functional interface since opaque types cannot be inspected outside of their source module. This is optional, but will allow to reuse the same interface to run a lazy filter through DB connections where the opaque type could be something like {db, Config, Connection, Query}. That data structure could lazily be built and actualized with real data through a distinct function call, without changing the interface. All that’s missing is a function to actualize the result set into a concrete type users are free to poke into:
-spec fetch(handle()) -> [employee()].
fetch({raw, Maps}) -> Maps.Notice how the opaque handle() type gets converted to a list of employees.
A single property could tie everything together for a last test:
prop_handle_access() ->
?FORALL(Maps, non_empty(list(raw_employee_map())),
begin
CSV = hexa_csv:encode(Maps),
Handle = hexa_employee:from_csv(CSV),
Partial = hexa_employee:filter_birthday(Handle, date()),
ListFull = hexa_employee:fetch(Handle),
true = is_list(hexa_employee:fetch(Partial)),
%% Check for no crash
_ = [{hexa_employee:first_name(X),
hexa_employee:last_name(X),
hexa_employee:email(X),
hexa_employee:date_of_birth(X)} || X <- ListFull],
true
end).The results look good too:
$ rebar3 do eunit -c, proper -c, cover -v
[...]
|------------------------|------------|
| module | coverage |
|------------------------|------------|
| hexa_csv | 100% |
| hexa_employee | 100% |
| hexa_filter | 100% |
|------------------------|------------|
| total | 100% |
|------------------------|------------|Vanity metrics always feel nicer than they should.
6.7. Templating
The last bit left to do before tying it all up is templating. The requirement is straightforward. Send an email whose content is just Happy birthday, dear $first_name!. The function should take one employee term and that’s it. Since the focus is on unit tests, only templating needs coverage for now:
-module(prop_hexa_mail_tpl).
-include_lib("proper/include/proper.hrl").
prop_template_email() ->
?FORALL(Employee, employee_map(),
begin
0 =/= string:rstr(hexa_mail_tpl:body(Employee),
maps:get("first_name", Employee))
end).
employee_map() ->
%% PropEr does not have a native map type, so we convert
?LET(PropList,
[{"last_name", non_empty(prop_csv:field())},
{"first_name", non_empty(prop_csv:field())},
{"date_of_birth", {choose(1900,2020), choose(1,12), choose(1,31)}},
{"email", non_empty(prop_csv:field())}],
maps:from_list(PropList)).The string:rstr/2 function looks for a given string within another one and returns its starting position (1-indexed). One gotcha is that some fields are defined as nullable in the employee module (they may return undefined). The initial specification did not mention it were possible or not for them to be missing, but since the sample of two entries all had fields, that is the assumption that wins.
With the following implementation, the test should pass every time:
-module(hexa_mail_tpl).
-export([body/1]).
-spec body(hexa_employee:employee()) -> string().
body(Employee) ->
lists:flatten(io_lib:format("Happy birthday, dear ~s!",
[hexa_employee:first_name(Employee)])).A trivially correct convenience function that extracts all that is needed for an email to be sent (address, subject, body) can be added to provide further decoupling:
-spec full(hexa_employee:employee()) -> {[string()], string(), string()}.
full(Employee) ->
{[hexa_employee:email(Employee)],
"Happy birthday!",
body(Employee)}.The email address is put in a list since e-mail clients typically allow more than one entry in the 'To:' field.
6.8. Plumbing it all Together
This section shouldn’t really be requiring unit tests, just integration tests, which we decided were out of scope for now.
-module(hexa).
-export([main/1]).
main([Path]) ->
{ok, Data} = file:read_file(Path),
Handle = hexa_employee:from_csv(binary_to_list(Data)),
Bday = hexa_employee:fetch(hexa_employee:filter_birthday(Handle, date())),
Mails = [hexa_mail_tpl:full(Employee) || Employee <- Bday],
[send_email(To, Topic, Body) || {To, Topic, Body} <- Mails].
send_email(To, _, _) ->
io:format("sent birthday email to ~p~n", [To]).The e-mail client is not implemented since it is also out of scope for now. The program can now be run (ensure the CSV file used has full CRLF line terminations):
→ rebar3 escriptize
===> Verifying dependencies...
===> Compiling hexa
===> Building escript...
→ _build/default/bin/hexa priv/db.csv
sent birthday email to ["born.today@example.com"]That works, albeit with a fake e-mail client. Coverage is good, critical parts are tested, and changing implementations will have limited effects in the testing code base.